在微服務架構中,數(shù)據(jù)處理與存儲服務不僅是業(yè)務的核心,也是可觀測性數(shù)據(jù)的核心源頭與關鍵承載者。一個設計良好的數(shù)據(jù)處理與存儲服務,不僅能高效、可靠地支撐業(yè)務,更能為整個系統(tǒng)的可觀測性提供堅實的數(shù)據(jù)基礎。本文將深入探討在.NET生態(tài)下,如何構建兼具高性能與高可觀測性的數(shù)據(jù)處理與存儲服務。
一、 可觀測性數(shù)據(jù)的三大支柱在數(shù)據(jù)服務中的體現(xiàn)
數(shù)據(jù)處理與存儲服務是可觀測性三大支柱——日志(Logs)、指標(Metrics)和分布式追蹤(Traces)的集中生產(chǎn)者和消費者。
- 日志(Logs):記錄服務處理數(shù)據(jù)的詳細過程,如數(shù)據(jù)庫連接狀態(tài)、SQL執(zhí)行情況(參數(shù)、耗時)、數(shù)據(jù)轉換邏輯、緩存命中/失效、異常事件等。在.NET中,可使用Serilog或NLog等結構化日志庫,將日志輸出為JSON格式,便于后續(xù)的解析與聚合。
- 指標(Metrics):量化反映數(shù)據(jù)服務的運行狀態(tài)與性能。關鍵指標包括:
- 服務級指標:請求速率(RPS)、請求延遲(P95, P99)、錯誤率。
- 數(shù)據(jù)存儲層指標:數(shù)據(jù)庫連接池使用率、慢查詢數(shù)量、緩存命中率、隊列積壓長度(如使用消息隊列時)。
* 資源指標:CPU/內(nèi)存使用率、GC頻率。
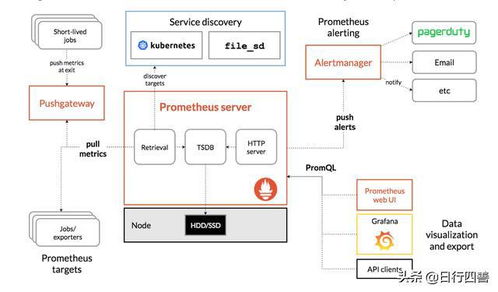
.NET中可通過OpenTelemetry .NET SDK或App Metrics庫輕松采集并暴露這些指標,通常以Prometheus格式提供。
- 分布式追蹤(Traces):在微服務間調(diào)用鏈中,清晰展示一次數(shù)據(jù)請求的完整路徑。例如,一個API請求可能依次經(jīng)過網(wǎng)關 -> 業(yè)務服務 -> 數(shù)據(jù)服務 -> 數(shù)據(jù)庫。通過OpenTelemetry或Application Insights,我們可以自動或手動為每個數(shù)據(jù)庫操作、緩存操作、消息發(fā)布/消費創(chuàng)建Span,從而精確定位延遲或故障發(fā)生在數(shù)據(jù)層的哪個具體環(huán)節(jié)。
二、 數(shù)據(jù)處理與存儲服務的可觀測性架構實踐
1. 數(shù)據(jù)訪問層的可觀測性增強
在數(shù)據(jù)訪問層(如使用Dapper、Entity Framework Core),應進行深度埋點。
- EF Core集成:利用EF Core的診斷監(jiān)聽器(
DiagnosticListener)或攔截器(DbCommandInterceptor),可以捕獲所有執(zhí)行的SQL命令、參數(shù)、耗時以及連接狀態(tài)變更,將這些信息作為Span發(fā)送到追蹤系統(tǒng),并記錄為結構化日志。 - 健康檢查:為數(shù)據(jù)庫、Redis緩存、Elasticsearch等外部依賴配置健康檢查端點。ASP.NET Core內(nèi)置的健康檢查中間件,結合AspNetCore.HealthChecks系列擴展包(如
AspNetCore.HealthChecks.SqlServer,AspNetCore.HealthChecks.Redis),可以實時反饋存儲服務的就緒狀態(tài)與存活狀態(tài)。
2. 異步消息處理的可觀測性
若數(shù)據(jù)服務涉及消息隊列(如RabbitMQ、Kafka、Azure Service Bus)進行數(shù)據(jù)同步或事件驅(qū)動處理,確保消息處理的可見性至關重要。
- 消息追蹤:在消息的Header中注入追蹤上下文(Trace Context),使得消息的生產(chǎn)、傳輸、消費全過程能被串聯(lián)到同一個Trace中。OpenTelemetry的傳播機制可以很好地支持此功能。
- 處理指標:監(jiān)控消息消費速率、處理延遲、死信隊列數(shù)量等指標,及時發(fā)現(xiàn)消費積壓或處理失敗。
3. 緩存層的可觀測性
對于Redis等緩存服務,需監(jiān)控:
- 性能指標:命令執(zhí)行延遲、網(wǎng)絡往返時間。
- 有效性指標:緩存命中率、內(nèi)存使用率、鍵過期與驅(qū)逐策略。
- 集成追蹤:在使用
StackExchange.Redis等客戶端時,可以通過封裝或使用支持OpenTelemetry的庫,將每個Redis命令記錄為一個Span。
三、 數(shù)據(jù)的存儲、聚合與可視化
生成的海量可觀測性數(shù)據(jù)需要高效的存儲與查詢方案。
- 日志存儲:結構化日志可發(fā)送至Elasticsearch、Loki或Azure Log Analytics,便于全文檢索和聚合分析。
- 指標存儲:Prometheus是云原生場景下指標存儲與告警的事實標準,其Pull模型適合服務暴露指標端點。對于大規(guī)模或長期存儲,可考慮Thanos或VictoriaMetrics。
- 追蹤存儲:Jaeger或Zipkin是專為追蹤數(shù)據(jù)設計的存儲與查詢系統(tǒng),能夠直觀展示調(diào)用鏈。Tempo也是一個新興的、與Prometheus生態(tài)緊密集成的選擇。
- 統(tǒng)一可視化:Grafana是連接以上所有數(shù)據(jù)源的絕佳儀表盤工具。通過配置不同的數(shù)據(jù)源,可以在一個界面中實現(xiàn)日志、指標、追蹤的關聯(lián)查詢與可視化,真正做到“三支柱”聯(lián)動。例如,從指標圖表中發(fā)現(xiàn)延遲飆升,可直接下鉆查詢該時間段的詳細日志和相關的慢追蹤。
四、 .NET技術棧集成示例
一個典型的.NET微服務項目可以通過以下方式集成可觀測性:
- 引入
OpenTelemetry.Exporter.Console、OpenTelemetry.Exporter.Jaeger、OpenTelemetry.Extensions.Hosting等NuGet包。 - 在
Program.cs中配置OpenTelemetry,添加對ASP.NET Core、HttpClient、EF Core、Redis等組件的自動檢測。 - 配置Serilog,將日志輸出到控制臺的也發(fā)送到Elasticsearch。
- 使用
Prometheus-net或OpenTelemetry.Exporter.Prometheus暴露指標端點。 - 在Grafana中配置Prometheus、Loki、Tempo數(shù)據(jù)源,并創(chuàng)建針對數(shù)據(jù)服務的專屬監(jiān)控儀表盤。
###
數(shù)據(jù)處理與存儲服務的可觀測性建設,并非簡單的工具堆砌,而是一種貫穿于設計、編碼、部署、運維全過程的工程實踐。在.NET微服務體系中,充分利用OpenTelemetry等標準化工具和云原生生態(tài),可以為數(shù)據(jù)服務構建起從代碼級細節(jié)到系統(tǒng)級態(tài)勢的立體化觀測能力。這不僅能快速定位和解決數(shù)據(jù)層面的故障與性能瓶頸,更能通過洞察數(shù)據(jù)流動規(guī)律,為系統(tǒng)的容量規(guī)劃、架構優(yōu)化提供至關重要的決策依據(jù),最終驅(qū)動整個微服務系統(tǒng)向更穩(wěn)定、高效、可信的方向演進。